Table Of Content
Autonomous technology frees up developers from the mundane tasks of managing the database. For instance, they no longer have to determine infrastructure requirements in advance. Instead, with a self-driving database, they can add storage and compute resources as needed to support database growth. With just a few steps, developers can easily create an autonomous relational database, accelerating the time for application development. Designing a database isn’t just about storing data, it’s about structuring that data in a way that makes sense. The process of Database Design is crucial for creating an efficient system.
SQL Tutorial Course from Craig Dickson
Their prevalence and longevity mean that relational databases are a mature technology, which is itself one of their major advantages. There are many applications designed to work with the relational model, as well as many career database administrators who are experts when it comes to relational databases. There’s also a wide array of resources available in print and online for those looking to get started with relational databases. Instead, we can create another table (say ProductDetails, ProductLines or ProductExtras) to store the optional data.
MySQL and PostgreSQL
Out of these super keys, we can always choose a proper subset among these that can be used as a primary key. If there is a combination of two or more attributes that are being used as the primary key then we call it a Composite key. Normalization was first proposed by Codd as an integral part of the relational model. It encompasses a set of procedures designed to eliminate non-simple domains (non-atomic values) and the redundancy (duplication) of data, which in turn prevents data manipulation anomalies and loss of data integrity.

Solve your business challenges with Google Cloud
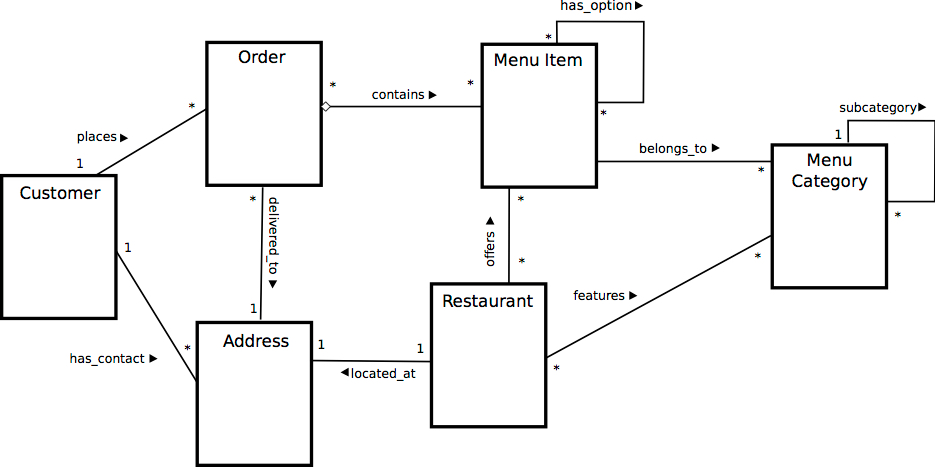
It allows users to establish links between different sets of data within the database and use these links to manage and reference related data. E.F. Codd proposed the relational Model to model data in the form of relations or tables. After designing the conceptual model of the Database using ER diagram, we need to convert the conceptual model into a relational model which can be implemented using any RDBMS language like Oracle SQL, MySQL, etc.
For the “Artists” table, the “Artist name” field is already a pretty good candidate for the primary field, as it’s pretty unlikely that your record label will sign two artists with the same name. We can also pick “Venue name” as the primary field for the “Venues” table. Whatever the case, it’s worth taking the time to identify the exact purpose of the database you’ll be creating. With so many options available, it can be challenging to choose a database solution that perfectly fits your needs.
Each of these have their pros and cons (and like everything coding-adjacent, their online hyper-partisans), and SQL is not implemented in exactly the same way in each of them. The concepts are the same, but the syntax and keywords may be slightly different, so it is not usually possible to use SQL code written for PostgreSQL in Microsoft SQL Server, for example, without making some modifications. If you build a house without finalizing the blueprints, odds are when it’s finally built the house will have questionable structural integrity. Similarly, taking time to think carefully about the design of your relational database before implementing it can save you a lot of trouble in the long run. In this tutorial, we’ll cover several design principles that you can follow to help you build better databases. A relational database is a type of database that focuses on the relation between stored data elements.
I have worked as a teacher of English as a Foreign Language in Berlin for some time, so this is an example which is near to my heart. When I first started using databases at work and writing SQL queries, I was always slightly terrified that I would accidentally delete all of the production data that my company relies on. As a result, I was very tentative about which queries I made and what I did. Over time, I learned more about how to use and interact with databases using some different flavours of Structured Query Language (SQL to its friends). Also, constantly adding new elements to a database can make it so complex it becomes difficult to form relations between new pieces of data.
Db2 and 50 Years of Relational Database Design - IBM
Db2 and 50 Years of Relational Database Design.
Posted: Thu, 25 Jun 2020 07:00:00 GMT [source]
Relational model
Databases and Data Modelling — A Quick Crash Course - Towards Data Science
Databases and Data Modelling — A Quick Crash Course.
Posted: Fri, 12 May 2023 07:00:00 GMT [source]
It’s natural for people who work with something every day to think of some things as ‘common sense’ or obvious, when they may not be obvious to someone coming from outside that area of work. Also, people might sometimes not be used to thinking about these aspects of their work with the rigour necessary to create a database. For the “Gigs” table, an artist could perform at the same venue on multiple occasions, so we should make a new field that gives a unique name to the specific combination of an artist at a venue on a specific date. Next, you want to figure out how to name your records in each table. Unlike other entries on this list, SQLite is not a client-server database manager but rather embedded into the end application.
SQLite, for example, only has about 3-4 native data types and it is one of the most commonly used environments these days due to its small size, portability, and the fact that it is built-in to browsers and mobile devices. On the other hand, we have the physical data design model which involves translating this logical model onto physical media using hardware resources and software systems such as DBMS (database management systems). By virtue of its product lifespan, there is more of a community around relational databases, which partially perpetuates its continued use.
The relational data model is the most widely used data model, and a vast majority of current database systems are based on the relational model. A relational database is a type of database that stores and provides access to data points that are related to one another. Relational databases are based on the relational model, an intuitive, straightforward way of representing data in tables. In a relational database, each row in the table is a record with a unique ID called the key. The columns of the table hold attributes of the data, and each record usually has a value for each attribute, making it easy to establish the relationships among data points.
The approach to exercises varies from chapter to chapter; many chapters include only a single, straightforward application problem, while a few others dig a little deeper. Relational databases handle business rules and policies at a very granular level, with strict policies about commitment (that is, making a change to the database permanent). For example, consider an inventory database that tracks three parts that are always used together. When one part is pulled from inventory, the other two must also be pulled. If one of the three parts isn’t available, none of the parts should be pulled—all three parts must be available before the database makes any commitment.
This is very helpful for ensuring data integrity when making changes to multiple rows or tables. The relational model’s structural elements help to keep data stored in an organized way, but storing data is only useful if you can retrieve it. To retrieve information from an RDBMS, you can issue a query, or a structured request for a set of information. As mentioned previously, most relational databases use SQL to manage and query data.
Navigation was typical of PDF documents and easy to move around and navigate throughout the document. Key terms for each section were conveniently located at the end of each section which explained the important terms. For intro to database awesome, but not for an advanced databases course. The texts covers all the topics required for an introduction to data base management course. As explained above in the "Accuracy" section, I worry that the explanations of key concepts were too short, not well organized, and therefore are likely to be unclear to beginners in this field.
The same column productID should be used as the primary key for both tables. One-to-many relationship cannot be represented in a single table. For example, in a "class roster" database, we may begin with a table called Teachers, which stores information about teachers (such as name, office, phone and email). To store the classes taught by each teacher, we could create columns class1, class2, class3, but faces a problem immediately on how many columns to create. However, since a teacher may teach many classes, its data would be duplicated in many rows in table Classes.
Queueing is a technique of storing data or tasks in a buffer or list, to process them sequentially or asynchronously. Queueing can help manage concurrency and load balancing, by distributing work among multiple workers or threads. Queueing can also help improve reliability and fault tolerance, by ensuring that data or tasks are not lost or duplicated in case of failures or interruptions. Queueing can be implemented using various technologies, such as message brokers, message queues, or distributed streaming platforms.
This is the reason that we store the foreign key on the table which is on the N side of a 1-to-N relationship. What makes a relational database relational is, you might not be surprised to learn, the relations between the data stored in the tables. For example, connected to our product table above, we may have a further table with all the details of all the brands that are sold in our store. We can create, read, update and delete (the basic functions of any database) the information in our relational database using a Relational Database Management System (RDBMS). Example of RDBMSs include Oracle, Microsoft SQl Server, MySQL, and PostgreSQL, among many others.








No comments:
Post a Comment